MapReduce 实验记录。
任务介绍
MapReduce 是一个基础而实用的分布式框架,它的核心思想是创建一个掌控全局的 master 和若干个打工仔 worker,master 通过网络通信调动 worker,实现高效的多线程并行化工作。
在本次 MIT 6.824 2020 Lab1 项目中,使用 go 语言搭建了一个基础分布式框架,用 rpc 进行通信,实现词频统计功能。
📚 附:MIT 6.824 Lab 1: MapReduce,知乎推荐参考资料(非常感谢思路!)
整体框架
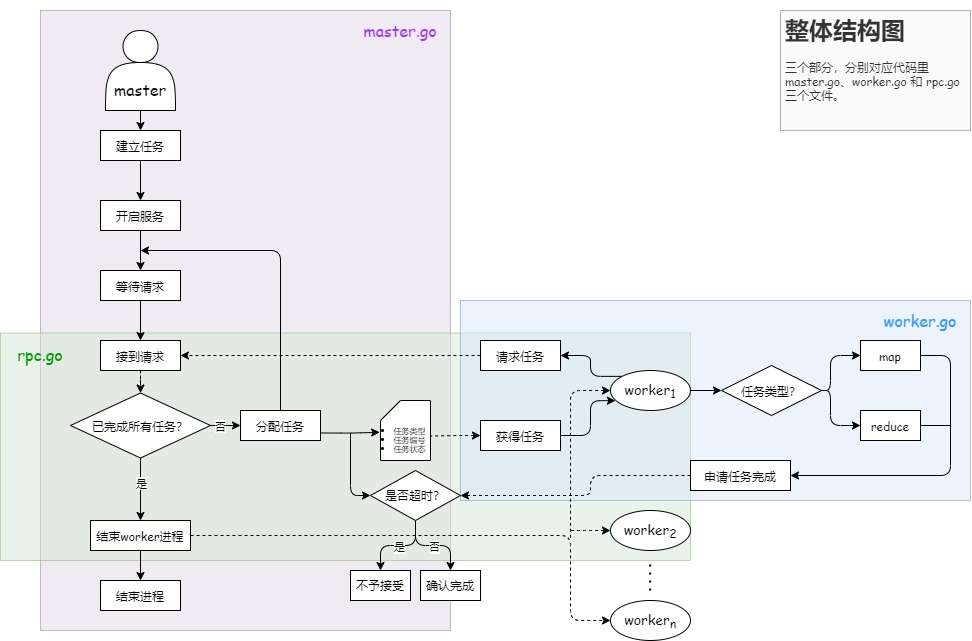
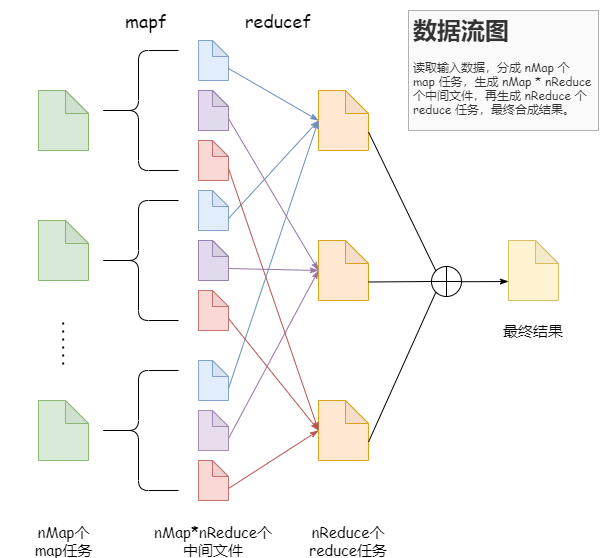
因为网络上关于 MapReduce 的参考资料很多,细节部分不多赘述,下面是我自己总结的两张流程图,作为补充。
整体结构图
数据流图
重难点记录
容错处理
定时追踪
goroutine 是 Go 语言中的轻量级线程实现,由 Go 运行时(runtime)管理。Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU。
1 | go 函数名( 参数列表 ) |
使用 go 关键字创建 goroutine 时,被调用函数的返回值会被忽略。如果需要在 goroutine 中返回数据,要使用通道(channel)特性,通过通道把数据从 goroutine 中作为返回值传出。
在项目中,用 goroutine 将 checkCrash 函数挂起,每隔一段时间(10s)就检查一次:如果任务还是 RUNNING 状态,考虑到任务工作量较小,说明负责该任务的 worker 遇到了点麻烦,不适合继续干这个任务了。于是,我们用小本本(CrashWorkers)将这个没完成 ddl 的 worker 记下,将任务重置为 UNDONE 状态,重新分配给来申请任务的其他 worker。
worker 可能遇到两种情况,导致任务在时限后仍为 RUNNING:
-
worker 在工作的时候突然退出了,没有向 master 发送完成任务的消息(已经杳无音讯了),任务就一直卡在 RUNNING 的状态。
-
worker 在工作时遇到了点障碍,耽误了时间,在 10s 后才完成任务。这之前,master 已经把任务状态重置了,可能任务已经分配给了其他 worker。前一个 worker 向 master 发送完成请求(CheckTaskFinished),请求保存文件并将任务置为 FINISHED,这时 master 通过查阅的 CrashWorkers 名单,拒绝它的请求。因为我们假定这个 worker 虽然犯了一次错误,但还是个好孩子,所以 master 将其移除名单,允许其改过自新、继续请求任务。
1 | // call for a task |
1 | // check a task is finished or not |
临时文件
考虑 worker 工作得慢被当作 crash 的情况。这个 worker 慢慢地进行计算,完成后想要写入结果,但是结果文件已经由新分配的快 worker 生成了。这时,若慢 worker 仍要写入,就可能对文件产生污染(在不创建新文件的情况下,Linux 是默认追加而不是重定向)。按照实验指南的提示,我们先创建临时文件,让 worker 将结果先写入临时文件中,待完成请求(CheckTaskFinished)通过后,将临时文件重命名为最终的名字;否则,直接删除临时文件。
1 | // worker.go |
1 | // master.go |
互斥锁
整个框架有很多共享变量,如每个任务的 TaskState,这个变量非常重要,由于它会受到多个线程 worker 的改变,我们采用互斥锁将涉及它的函数锁起来。
Mutex 是互斥锁的意思,也叫排他锁,同一时刻一段代码只能被一个线程运行,使用时只需要关注方法 Lock(加锁)和 Unlock(解锁)即可。
在 Lock() 和 Unlock() 之间的代码段称为资源的临界区(critical section),是线程安全的,任何一个时间点都只能有一个 goroutine 执行这段区间的代码。
1 | // 在函数体内加入此段代码,defer 保证函数结束后自动释放锁 |
Debug 之路
RPC 通信异常
最开始遇到的问题,代码里有特别强调: RPC通信模块中所有函数和变量名,首字母要大写。
1 | // |
程序运行速度慢,任务接收不正常
整个程序运行速度很慢。并且,将 worker 接收任务的过程打印出来,发现:worker 接收 map 任务和 reduce 任务的总次数,都大于实际所需次数。也就是说,任务被重复接收了。开始时,我考虑以下几种错误可能:
- 变量共享导致异常
- 任务分配过程有纰漏
排除了以上原因,我对程序进行打印调试,发现:
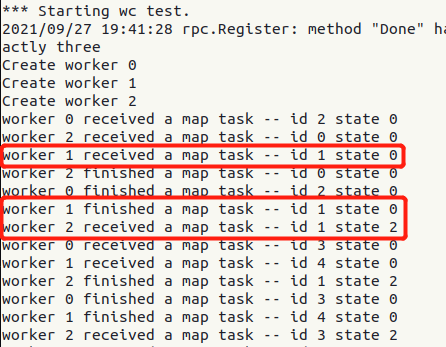
state 0 为未完成,state 2 为已完成。worker 1 接收了状态为 UNDONE 的任务 1 (事实上,传到 worker 时任务应为 RUNNING状态),worker 1成功完成了任务 1,但任务 1 并没有被成功设为 FINISHED 状态,后面另一个 worker 2 重复接收了任务 1 ,但此时任务 1 却是 FINISHED 状态的。我们的任务分配代码确实会将任务设为 RUNNING 再传出去,确实会将已完成的任务设为 FINISHED,也确实不会将 FINISHED 的任务重新分配出去。于是,这个现象令我感到非常疑惑。
最终发现:我在参考别人思路设计 crash 部分代码时,没有了解 goroutine 的使用,错将 go 并行调用函数当成直接调用函数来写。同时,我还在 checkCrash 函数中,将互斥锁加在了 Sleep 函数的前面。
错将 goroutine 写成普通单线程,master 的线程会被占住,不能继续进行调度工作,程序运行就会慢。
先申请互斥锁,再调用 Sleep 函数,在单线程中就会一直占住,变量TaskState也会被占住不能更新。worker 完成了任务向 master 汇报完成,但数据被锁住了,就没有及时更新为 RUNNING。
将互质锁位置更改后,输出如下:
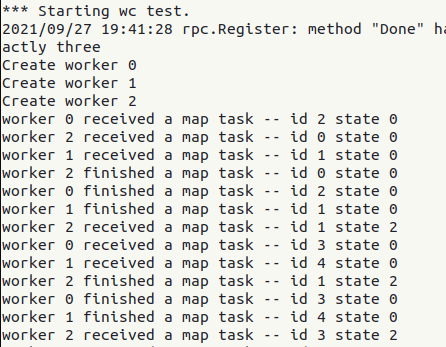
这时,任务永远卡在了 RUNNING 状态!
继续将 go m.checkCrash(reply.ReceivedTask, workerID) 更改后,程序正常运行。(这部分想努力捋清楚原因,碍于时间,先挖个坑。)
修改后代码如下:
1 | // worker ask for a task, send a specific task |
1 | // check crash or not |
临时文件没有全部删除
用 ioutil.TempFile 函数在系统的/tmp路径建立临时文件,后面 os.Rename 函数就会将其删除。
1 | tmpFile, err := ioutil.TempFile("", tmpFileName) |
实际上,在 crash-test 中,我的临时文件并没有删除干净。因为我在 reduce 任务中,是先打开文件,一边运行 reducef 函数,一边写入文件。
查看 crash.go,研究其 crash 机制:有 1/3 的几率是直接退出,有 1/3 的几率是停顿 [0, 10] s。
1 | // crash.go |
reduce 任务中要执行包含的 key 数量这么多次 reducef 函数,crash 直接退出后,这个线程完全失联,不返回临时文件名,自然没办法删除。因此,这里采用一个策略,先把 reducef 后的结果保存好,再创建临时文件写入,这样即使前面 crash 了,也不会留下可怜无人管的临时文件。
1 | // use a temp array to save reducef results |
connection refused
1 | 2021/09/30 10:28:50 dialing:dial unix /var/tmp/824-mr-1000: connect: connection refused |
这个报错是 worker 调用 call 函数向 master 通信失败产生的,通常原因是 master 已退出而 worker 还没退出。在我原本的代码中,master 向完成最后一个任务的 worker 发送了退出指令,短时间内 Done 函数返回 true 值,master 就直接溜之大吉了。这导致其他来请求任务的 worker 没有收到返回指令,产生报错。
虽然不影响最终结果,但是考虑到通信接口可能会受到干扰,我在 Done 函数中增加了等待时间,等待其他 worker 前来,一个个告诉它们:”活干完啦,快下班吧“。
这里设置为等待一秒是因为我的 WAITTASK 设置为 1s,刚好能覆盖住所有 worker。
1 | // main/mrmaster.go calls Done() periodically to find out |
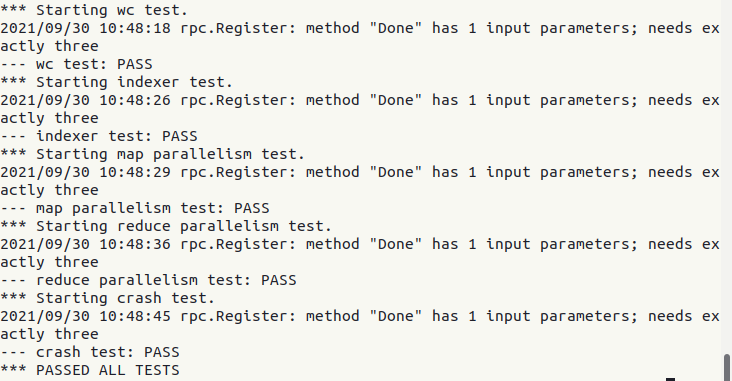
PASSED ALL TESTS