
这周讲座是由实验室的齐浩然师兄带来的,一场非常完整的对人脸超分辨领域的介绍,师兄讲得也很细致,讲得很好。
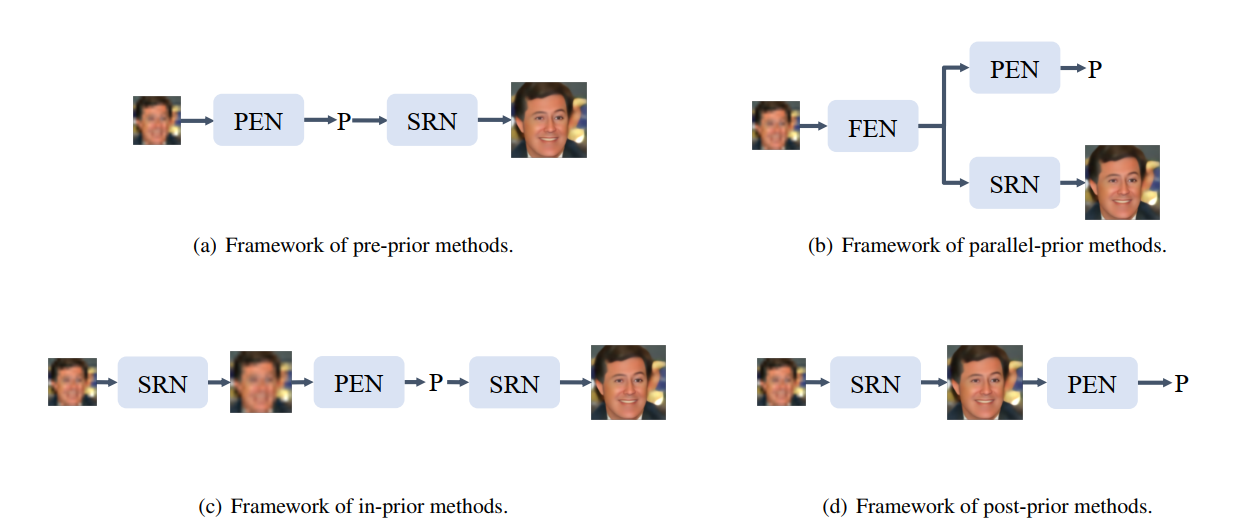
最后提到,这4种框架,能否应用到其他领域上来:
- pre-prior
- parallel-prior
- in-prior
- post-prior
其中,后两种框架适用于LR质量过低、无法提取有效先验信息的情景中。
如图像去雨去雾,要结合深度信息,可以思考变换加入先验信息的形式。
我的思考:
第4种框架有点像我正在做的结构,检测出的人脸框作为P,进行误差计算。
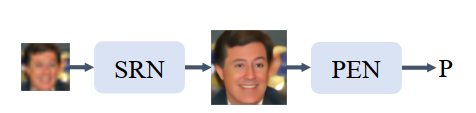
不同之处在于,我的框架在中间图像处也加了约束。(我觉得这种方法肯定也有,只是图中没有重点介绍)
换成pre-prior
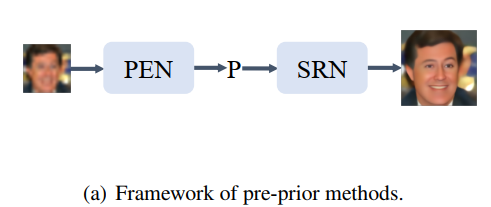
先人脸检测,检测结果作为先验信息再弱光增强。这个框架在我的任务中明显不可行,原因和人脸超分类似,黑暗图像检测出的人脸太少了,不足以作为先验信息。
换成parallel-prior:
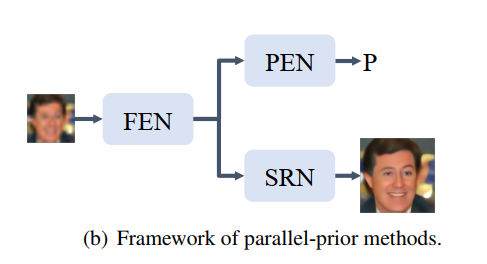
同时提升视觉效果和检测效果。
换成in-prior
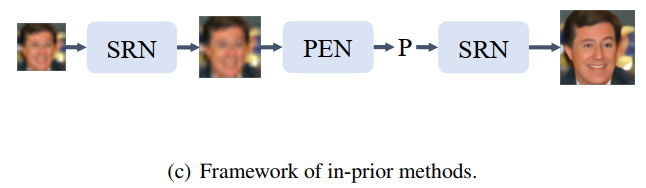
先对图像进行弱光增强,再进行人脸检测。增加步骤,将人脸检测结果作为先验信息一同再次放入增强网络,最终得到生成图像。
这种框架,我觉得是有利于最终的视觉效果,而这种视觉效果会反映利于检测的视觉提升方向。
总结:
先把手头的框架做完,可以来实验parallel-prior和in-prior,研究视觉提升和检测提升的协同性。