
最近偶然间在CSDN看见一个有意思的小项目:用GAN来生成MNIST手写数字。这个小项目既是之前MNIST分类问题的拓展,又能尝试亲手写一个GAN,还挺有意义。
代码参考自这篇博客,它的整体结构都很清晰,值得参考。
但是,在用这份代码时产生了一个问题:
问题:训练时生成器的损失总是较大,且不再下降,生成结果差。
原因分析:
给判别器喂real数据时出现问题。因为输入MNIST图像是黑底白字的,转换为tensor后,黑色像素对应的值为0,导致tensor中存在大量0。这些tensor输入神经网络后,造成神经元的死亡,无法继续训练。
将tensor值从[0,1]映射为[-1,1]后,输入tensor的值就是一个含大量-1的矩阵,就能正常训练了。(可打印进行验证)
解决方案:
将代码
1 | logits_real = D_net(real_data) |
改为
1 | logits_real = D_net(2 * (real_data - 0.5)) # 从[0,1]映射为[-1,1] |
训练效果对比:
- 前
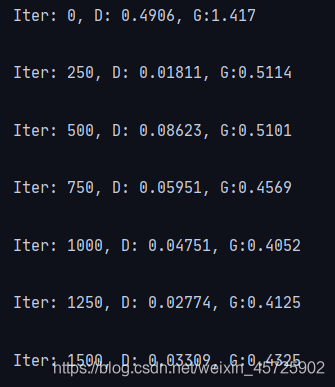
越训练图像越模糊,一定是训练过程出了问题:



- 后
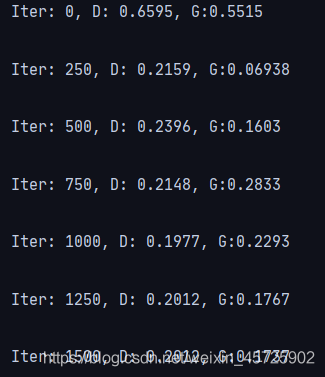
正常训练了!!



模型分析
Generator
Linear–>ReLU–>BatchNorm–>Linear–>ReLU–>BatchNorm–>reshape–>ConvTranspose–>ReLU–>BatchNorm–>ConvTranspose–>Tanh
Discriminator
conv–>LReLU–>MaxPool–>conv–>LReLU–>MaxPool–>reshape–>Linear–>LReLU–>Linear
摸鱼笔记
- 什么结构适合做生成,什么结构适合做鉴别,还需要积累知识。
- 观察生成结果,可以发现GAN的一些有趣的特性。
长得像“8”的“0”

想长成"0”的“6”

这个是…斯凯奇打钱???

甚至学会了竖中指…

可见我们的GAN宝宝在学习的时候,是完全不知道自己在学什么的。生成器在判别损失的引导鞭策下,去生成那些"看上去更可能真实”的图像。我觉得是因为模型本身的局限性,没办法避免这些奇奇怪怪符号的产生,因为它们在计算机看来的确像是一些“手写数字"(maybe火星人的手写数字)。按照我的猜想,模型的设计使得计算机不能完美地区分这些符号与真正的手写数字间的区别,那么提升模型的性能、优化模型的结构,应该能够提升生成结果的质量吧!(挖坑中)